業務にてRuby on Railsの Webアプリケーション開発していて、DB設計資料やER図を必要に応じて手で作って説明に利用したりしていました。
システムの運用も始まり、そろそろ手で作ることによる更新が厳しくなってきた感じがするので、自動生成できないかなあと思っていました。
今回は、CIプロセス(CircleCI)の中でSchemaSpyというツールを用いて、ドキュメントを自動生成してみたので、学びを書き残しておきます。

SchemaSpy
SchemaSpyというものを見つけました。
テーブル、カラムの構成情報やER図といったドキュメントをHTML/JS/CSSとして静的に出力してくれるツールです。実際にサーバー上で動いているDBを指定するとドキュメントを生成してくれます。
Javaで作られていているツールですが、公式でDockerコンテナイメージを公開してくれているので、簡単にCircleCIなどで実行できます。
手元で動かす
まずは、Rails アプリケーションのバックエンドとなっている MySQLが立ち上がっている状態で、そのDBに対して SchemaSpyの作成コマンドを実行してみました。
docker コマンドが動く環境で、以下のようにたたきます。
(手元の環境は、mac OS 10.15.7 で、MySQL 5.7でした)
$ docker run -v "$PWD/schema:/output" --net="host" schemaspy/schemaspy:snapshot -debug -t mysql -host 127.0.0.1:3306 -db 【DB名】 -u 【ユーザー名】 -p 【パスワード】 -connprops useSSL\\=false -s 【DB名】
すると実行したディレクトリ直下に schemaディレクトリが作成され、その中の index.html をブラウザで開くと作成されたドキュメントを確認することができます。
簡単ですね。
最新のドキュメントをいつでも見たい
ここまで来ると、後はDB構成に変更があってもいつでも最新のドキュメントを用意しておきたい気持ちになります。
最終的には冒頭でも書いたとおり、CircleCIで実行発行してホストすることになりましたが、Railsアプリケーションでやろうとするといくつか問題もありました。その紆余曲折含めて最終的にどう実現したかを紹介します。
コマンドを実行する対象のDBを準備する必要がある
ドキュメント作成時、実際にサーバー上で動いているDBを指定する必要があります。
最新のドキュメントをいつでも見られるようにするための、選択肢としては以下の3つくらいを上げていました。
- A案)CI環境でドキュメント作成用のDBを一時的に立ち上げる
- B案)ステージング環境などのDBに定期的にコマンドを実行する
- C案)スキーマに変更があったとき毎回ローカルのDBに対してコマンドを叩く
C案は自動化とはいえなさそうなので却下して、A案かB案になります。
わざわざこのために実行環境を用意するのも嫌だなという気持ちになって、最終的にA案に落ち着きました。
SchemaSpyでは、稼働しているDBに対して実行することでテーブルごとの行数も見れますが、本番の情報ではない限りその情報はあまり意味もないので、すべてのテーブルが0行になっていてもドキュメントとして致命的な問題ではないということにしました。
今回はCircleCI上で実現しようということで、最終的なコードとしては、以下のようなjobの定義になりました。
(省略) build-erd: docker: - image: schemaspy/schemaspy:snapshot user: root - image: mysql:5.7.12 <<: *dockerhub_auth environment: MYSQL_DATABASE: xxxx_test MYSQL_USER: root MYSQL_ROOT_PASSWORD: password working_directory: ~/repo steps: - checkout - run: apk add openssl mariadb-client - run: sleep 5 - run: cat ./db/structure.sql | mysql -h 127.0.0.1 -P 3306 -u root -ppassword xxxx_test - run: cd / && schemaspy -t mysql -host 127.0.0.1 -port 3306 -u root -p password -db xxxx_test -s xxxx_test -hq -connprops useSSL\\=false - store_artifacts: path: /output (省略)
MySQLのコンテナを傍らで動かしつつ、SchemaSpy のコンテナの中でいくつかの処理を実行することになります。
Railsのスキーマフォーマットを変更する
SchemaSpyのコンテナからMySQLコンテナに対して、何らかの方法でSQLを実行し、DBを準備する必要があります。
SchemaSpyを利用されている例をいくつか調べてみると、DDLの形式のSQLファイルを手元でdumpしてリポジトリに含めておく、という運用をされているのが観測できました。
ローカルのDBをもとにダンプしてしまうのは、結局手で運用する部分がのこったり、開発者の考えることが増えると考えました。
Railsのデフォルトだと、db/schema.rb というスキーマファイルを bin/rails db:setup(の中のbin/rails db:schem:load)で読み込んで反映することになります。しかし、これをそのままやろうとすると、SchemaSpyのコンテナにRubyの環境を構築する必要があり、すこしつらそうという印象を持ちました。
他の方法を検討すると、Rails には db/structure.sql という別のスキーマフォーマットがあることに気づきました。
Railsには、config.active_record.schema_formatという設定があり、:sqlと:rubyを選択でき、それによって、structure.sqlとschema.rbの違いが出てきます。
デフォルトは:rubyですが、config/application.rbに以下のように書くことによって、設定を変更することができます。
class Application < Rails::Application config.active_record.schema_format = :sql end
ドキュメント自動生成のためにスキーマフォーマットを変えるのはどうかな、とも思いましたが、調べてみると、デメリットとしては手元でのスキーマファイルのコンフリクトが少し難しくなる程度でした。
structure.sqlでは、むしろメリットとして schema.rbでは表現しきれないDBの機能まで表現できるということで、特にこの変更は問題ないだろう、というふうに考えました。(実際そういった高度なDBの機能は使っていませんが。)
*1
Active Record マイグレーション - Railsガイド
Pros and Cons of Using structure.sql in Your Ruby on Rails Application | AppSignal Blog
これによって上記のようなjobの設定で、CircleCI上にSchemaSpyで生成したドキュメントをホストすることができました。
その他
sleep 5 ?
job の設定で、 sleep 5という謎のコマンド実行があります。
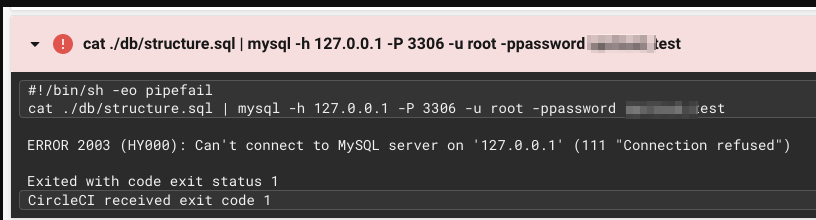
上記のようなエラーが出てしまい、MySQLが立ち上がりきっていない段階でコマンドを実行してしまっているのかなと考えて、足しています。
https://circleci.com/docs/ja/2.0/executor-types/
CircleCI公式のドキュメントでもmongoの立ち上がりを待っているような記述もあって、それに習ってこの対応をしていますが、5秒以上かかったらどうするんだ、という気持ちがあるので、あるべきやり方をご存知のかたいらっしゃったら教えてほしいです。
そんなに頻繁にスキーマ変更するの?
pushごとに毎回ドキュメントを生成するのかという話があると思います。確かにそんなに頻繁にスキーマの変更は起こらないので、追加で db/structure.sqlの変更差分があるときのみドキュメント生成を実行するということにしました。
CircleCIにはスケジュール実行の機能があったりするので、そちらを利用しても良いかもしれません。
終わり
これで、Rails の DB関連のドキュメントを自動メンテナンスする基盤が整いました。参考になると嬉しいです。
今のまま、CircleCI上にホストすると、せっかくのドキュメントの導線が埋もれてしまうので、ドキュメントを生成したタイミングでSlackなどにリンクを通知したり、S3などに上げてURL固定で最新のドキュメントを参照できるようにしたりなどもう少し改良の余地があるかなと思っています。
参考
https://engineering.mercari.com/blog/entry/2018-05-25-133818/





